Echo
Diffusion-based text-to-speech with fast, high-fidelity voice cloning
Overview
Code: https://github.com/jordandare/echo-tts
Demo: https://huggingface.co/spaces/jordand/echo-tts-preview
Recently, we have been working on a diffusion text-to-speech model, named Echo, following our prior work on Parakeet. This work was made possible through the TPU Research Cloud (TRC) program
Parakeet, which is autoregressive in DAC token space
We train a 2.4B DiT, Echo, that is able to generate audio segments of up to 30 seconds, conditioned on target text and up to two minutes of speaker reference audio. We generate Fish Speech S1-DAC latents and as a result are able to produce 44.1kHz audio.
Our model is quite fast at generating single samples (at least relative to frontier open-source autoregressive approaches). For example, given a 120-second audio prompt, we are able to generate 30 seconds of audio in only 1.45 seconds on an A100 (RTF < 0.05).
Below are samples, and further below is a more detailed description of the model.
Samples
Samples (showcase)
These samples have been minimally cherry-picked to showcase strengths and capabilities of our model. (Many of the samples were generated on the first try; CFG was adjusted from default settings in the singing and videogame character examples1. First-try outputs can be found in the sample comparisons section below.)
Podcast 0 — [S1] I'm not trying to make a good statement about the current....
[S1] I'm not trying to make a good statement about the current. [S2] Yeah, yeah, yeah. [S1] For, uh, operant, but maybe I am. But, like, the actual level of understanding is very different from the level of control. [S2] Yeah, I think that's fair. That's a good pushback. I think, like, um, I guess I expect loss of, uh, both. [S1] Mm. [S2] (laughs) Yeah. [S1] How come? I mean, loss of understanding is obvious, but why loss of control? [S2] So, uh, so we're really far into a territory of, uh,
Podcast 1 — [S1] But the in-context learning itself is not gradient descent, in the...
[S1] But the in-context learning itself is not gradient descent, in the same way that our lifetime intelligence as humans, to be able to do things, is conditioned by evolution, but our actual learning during our lifetime is like- [S2] Yeah. [S1] ... happening through some other process. [S2] I actually don't fully agree with that, but you should continue with how- [S1] Oh, okay. [S2] (laughs) [S1] I, actually, then I, I'm very curious to understand how that analogy breaks down. [S2] I think I'm hesitant to say that in-context learning is not doing gradient descent,
Podcast 2 — [S1] pre-training helps build the kind of entity which can learn better....
[S1] pre-training helps build the kind of entity which can learn better. It teaches meta-learning, and therefore it is a sim- similar to like finding an algorithm. [S2] Mm-hmm. [S1] Um, but if, if it's like evolution gives us knowledge and pre-training gives us knowledge, they're not, that analogy seems to break down. [S2] Yeah, yeah. So it's subtle, and I think you're, you're right to push back on it, but basically, the thing that pre-training is doing, so you're basically getting the next- [S1] Yeah. [S2] ... token predictor on, over the internet, and you're training that into a neural net.
Reading 0 — [S1] The old lighthouse keeper had seen many storms in his thirty...
[S1] The old lighthouse keeper had seen many storms in his thirty years on the rock, but nothing like this. The fog rolled in thick as wool, swallowing the beam of light before it could reach the churning waves below. Then he heard it, three short bells from the channel, where no ship should be at this hour. Something was out there, something that shouldn't exist.
Speaker 0 — [S1] And they don't do a lot of the things that you've...
[S1] And they don't do a lot of the things that you've alluded to earlier, you know. They don't have continued learning. You can't just tell them something and they'll remember it. And they're just cognitively lacking, and it's just not working. And I just think that it will take about a decade to work through all of those issues. I could be wrong (laughs).
Speaker 1 — [S1] (singing) The LLM will often give you some stuff, which is...
[S1] (singing) The LLM will often give you some stuff, which is roughly correct. (singing) But if you give it the full chapter and ask it questions, you're going to get much better results because it's now loaded in the working memory of the model.
Speaker 2 — [S1] Actually, recently, I, uh, also went back all the way to...
[S1] Actually, recently, I, uh, also went back all the way to 1989, which was kind of a fun, uh, exercise for me a few years ago, uh, because I was reproducing, uh, Jan LeCun's 1989 convolutional network, which was the first neural network I'm aware of trained via gradient descent, like modern neural network-trained.
Samples (comparisons)
For each (reference-audio, text-prompt) pair, we sample from Echo, Higgs Audio v2, and VibeVoice-7B
In our opinion, Echo is able to capture the reference speaker qualities (and generate correct semantics) fairly well. There is an artifact around “or not” in the Echo-generated podcast_0 samples; this artifact is eliminated by increasing the number of sampling steps from 30 to 60 (which still only takes 2.7 seconds on an A100). See footnote for the 60-step audio (same random seed, first-try with 60 steps).3
These prompts are stylistically “in-distribution” of Echo, and it’s likely that better samples for the other two models could be obtained via prompt (or hyperparameter) optimization.
The samples below take 1.45s, ~12s, and ~55s to generate on an A100 for Echo, Higgs Audio v2, and VibeVoice-7B respectively in our setup (per 30 seconds of audio). More optimized implementations may yield some speed-up for the other two models.
Podcast 0 — [S1] I, I think this, I think this was probably public. Uh,...
[S1] I, I think this, I think this was probably public. Uh, but basically, if you're using an LM judge for a reward, so you just give it a solution from a student and ask it if the student did well or not. We were training with reinforcement learning against that reward function, and it worked really well, and then, um, suddenly, the reward became extremely large. Like it was massive jump and it did perfect. And you're looking at it like, "Wow, this, this means the student is perfect in all these problems. It's fully solved math."
Podcast 1 — [S1] That's actually more boilerplate-y. So actually vibe coded part, partially some...
[S1] That's actually more boilerplate-y. So actually vibe coded part, partially some of that stuff. That was fine. Um, because it's not like mission critical stuff and it works fine. And then the other part is when I was rewriting the tokenizer in Rust, uh, I'm actually not as good at Rust because I'm fairly new to Rust.
Reading 0 — [S1] Deep beneath the ocean's surface, where sunlight fades to perpetual twilight,...
[S1] Deep beneath the ocean's surface, where sunlight fades to perpetual twilight, extraordinary creatures have evolved in ways that defy imagination. Bioluminescent jellyfish pulse with ethereal blue light, while giant squid hunt in the crushing darkness. At depths of over two miles, the pressure is immense, yet life persists.
Reading 1 — [S1] The telegram arrived on a Tuesday morning in June, nineteen forty-three....
[S1] The telegram arrived on a Tuesday morning in June, nineteen forty-three. Margaret's hands trembled as she tore open the envelope, dreading the words she knew might be inside. Her brother had shipped out to North Africa six months ago, and his letters had grown increasingly sparse. The weight of the war pressed down on everyone in the village, a collective holding of breath, waiting for news that could shatter families in an instant.
Sport 0 — [S1] Yeah, you know, um, look, we, we had our chances early....
[S1] Yeah, you know, um, look, we, we had our chances early. Got guys on base, uh, just couldn't really capitalize. Tommy's been throwing the ball well all season, right? He just, uh, he left a couple pitches up and, and they made us pay.
Character 0 — [S1] I think they might be the same contractor. No problem officer....
[S1] I think they might be the same contractor. No problem officer. Just glad we got this tightened out. I'll contact the ICP database immediately. Call back tomorrow. Hopefully they have dug up something useful to your investigation by then. The only constant seems to be that the mercenaries are always deployed in small countries.
Character 1 — [S1] After giving everything some more thought, I've decided it's in the...
[S1] After giving everything some more thought, I've decided it's in the best interest of humanity to acquire Nexus AI. Yes. I've spoken with the CEO and he's on board. Well, at least that's the impression he gave initially.
Details
Dataset
We collect a dataset consisting of around 160K hours of podcast-like audio. Similar to Parakeet, we split the data into (≤) 30-second segments and transcribe all segments individually with (our) WhisperD
Autoencoder
We use the Fish-Speech S1-DAC autoencoder
We choose to encode/store/load all of our data discretely as codes. Since we will use diffusion to model the data, we will need to represent the codes as continuous latents. Similar to DAC, S1-DAC forms its pre-decoder continuous latent by summing individual up-projections of each of the 10 codebook entries; these entries themselves have dimension 8, and are up-projected to dimension 1024. Thus, the resulting 1024-dimensional output subspace must have rank ≤ 80. We hoped to (in some sense) preserve the geometry of the pre-decoder latent space, so rather than concatenate codebook entries, we apply PCA to the pre-decoder latents and extract the first 80 indices of the rotated latents.4
Model
Echo is a 2.4B DiT
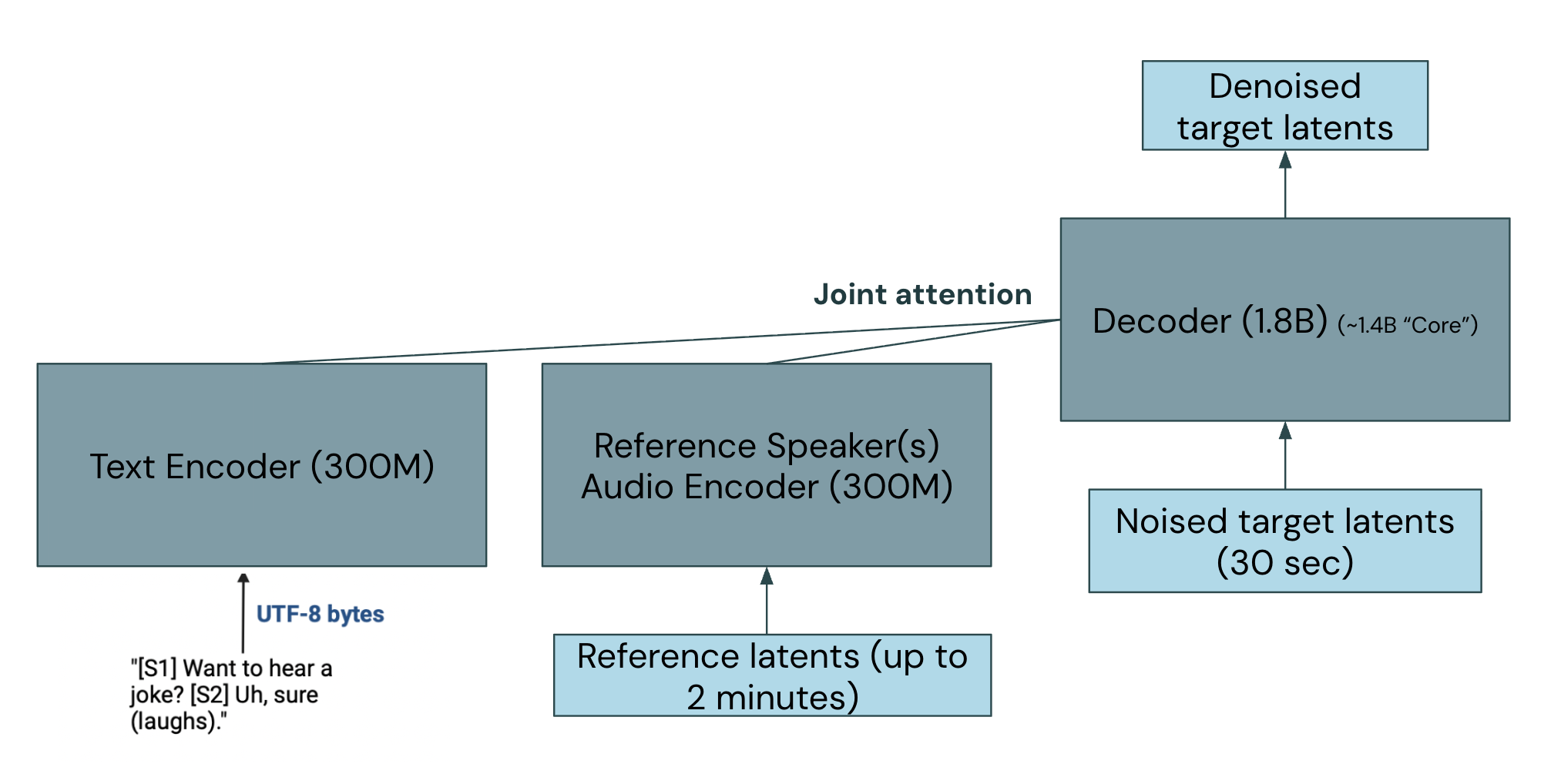
Echo consists of a speaker reference transformer, text transformer, and diffusion decoder:
- The speaker reference transformer processes up to two minutes of (clean) speaker reference latents. This originally corresponds to a latent sequence length of 2560. To reduce sequence length relative to target, we patch these latents (patch_size = 4) so that the transformer sequence length is 640. This encoder is causal.6
- The text transformer processes utf-8 bytes of maximum length 768 during training, with bidirectional attention (and appropriate masking).
- The diffusion decoder denoises noised latents (sequence length 640). It is a traditional transformer with:
- Self-attention replaced with joint-self-cross-attention, where the keys/values consist of the self(denoiser) keys/values concatenated with the speaker and text transformer output keys/values.7
- AdaLN with LoRA
to reduce param count, with a tanh applied on gate.
We use a SwiGLU MLP
Speaker reference selection
We need training tuples of the form (speaker_reference_audio, target_text, target_audio); while we have the target text and audio from the aforementioned segmentation, extracting speaker reference audio is slightly more involved. At this stage, our data consists of long audio samples (generally 30–60 minutes, think podcast-like; we will use the term “episode” moving forward) that have been segmented into <30-second clips. The most naive approach is to, for a given target clip, randomly select a subset of (distinct) segments from the same episode and concatenate up to 120 seconds of latents. This works reasonably well, though we try to improve upon this by diarizing each episode and selecting other clips based on a fuzzy/heuristic approach that tries to match speaker composition of reference concatenation and target.8
The upside of such a setup is that it is simple and allows us to drop in any single-or-multi-speaker audio clip(s) as speaker reference, without any additional labeling/transcribing/processing. The downside is that if we have two speaker reference clips where the speakers are in different “acoustic environments” and use the concatenation of these clips as the speaker reference, generating conversation between the two speakers is likely out-of-distribution for the model. Another downside is that given a reference clip of two speakers conversing, there is little (if any) control over the correspondence between [S1], [S2], …, and the reference speakers, and sampling over different random seeds might be necessary to obtain a desired permutation.
That said, these two missing behaviors/functions could be (relatively) straightforwardly fine-tuned into the model given the proper data. (And it might be possible to synthesize such data via diarization and audio augmentation.)
Training
We train on a TPU v4-64 pod in JAX/flax (linen). We use Muon
Since many audio segments are less than 30 seconds (i.e., latent sequence length < 640), we zero-pad all latent sequences to length 640 and treat this padded, fixed-sized latent as the denoiser target. During inference, we sample starting from noise with shape (batch, 640, 80), and crop the generated audio by heuristically identifying trailing regions of (near) zeros in the generated latent.
We train with a Rectified Flow setup
Sampling
We try a few different sampling methods, generally consisting of Euler sampling with the RF ODE. Below is an example of sampling hyperparameters.
- Number of steps (30 generally works well)
- CFG (select one version below)
and choose guidance scales - Joint unconditional (2× NFE)
-
v_pred = v_pred_cond + w * (v_pred_cond - v_pred_uncond)wherev_pred_unconddrops both text and speaker conditions
-
- Independent guidance (3× NFE)
v_pred = v_pred_cond + w_text * (v_pred_cond - v_pred_uncond_text) + w_speaker * (v_pred_cond - v_pred_uncond_speaker)
- Alternating guidance (2× NFE)
-
v_pred_cond + w_M * (v_pred_cond - v_pred_uncond_M)whereMalternates between text and speaker each step
-
- Joint unconditional (2× NFE)
-
CFG_min_t,CFG_max_t(we find 0.5 for min T often works well) -
initial_noise_scale- (sometimes scaling the initial noise by a factor of 0.8 or 0.9 reduces artifacts; as far as I understand, this is totally unprincipled and suggestive that something is “off”; should be looked into further)
- Temporal score rescaling
- Anecdotally (and with low confidence)
k = 1.2, sigma = 3.0may result in more robust/consistent/less-“artifacty”/flatter samples, whilek = 0.96, sigma = 3.0results in sharper samples (maybe higher cloning potential/ceiling for certain voices)?
- Anecdotally (and with low confidence)
We have not conducted a formal evaluation of different sampling hyperparameters. In our experience, the “Independent guidance” CFG option works well and has the benefit of decoupling the text and speaker guidance scales (though alternating guidance also decouples, and even joint unconditional CFG seems to work well in many cases). We have also at various points tried APG
(Dynamic-)Block-wise diffusion
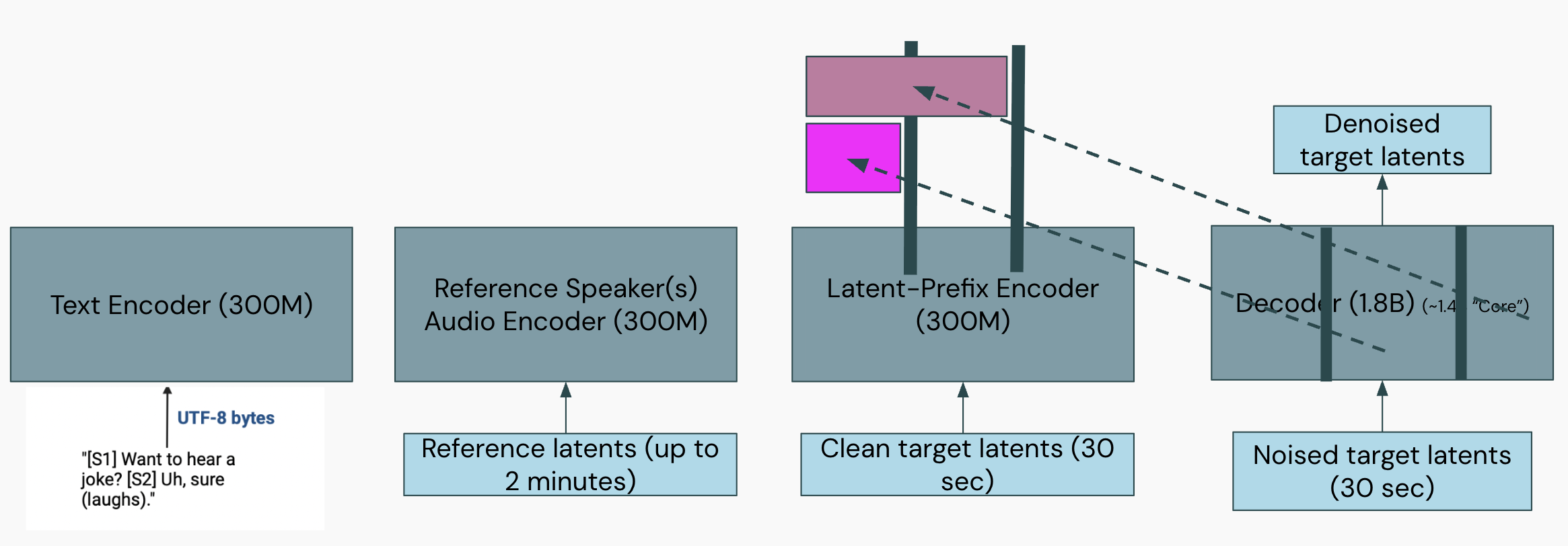
Our model as described above has the following limitations:
- It always will generate (zero-padded) 30-second chunks, even when the user anticipates the content will be much shorter (this still will generate proper-length content but spends more compute than necessary; consider time-to-first-byte (TTFB)).
- We cannot generate audio continuations (e.g., audio from seconds 10 to 20 given audio from the first 10 seconds). This also hinders generating longer-than-30-second samples via overlapping window approaches.
We propose fine-tuning Echo to perform dynamic-block-wise diffusion, which addresses both these points.
Specifically, we introduce a latent-prefix encoder (which shares the same architecture as the speaker reference encoder) that will causally process the clean (640, 80) target latents.9 During fine-tuning, we randomly partition x_t ∈ (640, 80) into (up to) 3 separate segments10 with block indices (0, 1, 2). In the decoder joint-self-cross-attention, the noised latents only can attend to other noised latents within the same block. We extend the existing keys/values with the (kv-projected) latent-prefix outputs11 and mask so that each noised latent attends only to latent-prefix keys from (strictly) previous blocks.
This allows us to specify any block-size to generate at inference: We simply process all previously generated (or given) latents with the latent-prefix encoder12 and then sample from the RF ODE with initial x_t ∈ (desired_length, 80)13. Since S1-DAC is causal, we can stream blocks of generated audio. If we want to decrease TTFB, we can first generate a short block and immediately decode it (and then generate longer blocks if desired).
To fine-tune this behavior, we initialize the latent-prefix encoder from the speaker reference encoder, initialize new w_k_latentprefix/w_v_latentprefix, and adapt the latent-prefix encoder (along with the MLP/attention of the decoder) with LoRA (all weights besides the LoRA layers and new w_k/w_v are frozen). We add RoPE (with patch-adjusted frequency) to the latent-prefix keys. We fine-tune with Adam for 100K steps. (Earlier versions of our training setup employed block-wise methods during pretraining, but for Echo we chose to leave this for fine-tuning.)
It is unlikely that we will include the block-wise fine-tuned weights in our initial release.
Acknowledgments
We are immensely grateful to the TPU Research Cloud program for their continued support. We’d also like to thank Professor Duan, Ge Zhu, and the AIR lab (https://labsites.rochester.edu/air/) at University of Rochester. Lastly, we thank Anaheim and https://huggingface.co/MrDragonFox from the OpenSesame audio research Discord server for their valuable early feedback and advice.
Audio reference samples are brief excerpts used for technical demonstration purposes only. All rights belong to original creators.
Bibtex
To cite this blog post, please use:
bibtex @misc{darefsky2025echo, author = {Darefsky, Jordan}, title = {Echo-TTS}, year = {2025}, url = {https://jordandarefsky.com/blog/2025/Echo/} }
-
Interestingly, in examples such as the videogame example where the text appears out-of-distribution for the speaker, the model will often ignore the speaker prompt and generate a speaker it deems more fit. To mitigate this, one can try a combination of increasing speaker CFG, decreasing text CFG, and/or using alternating guidance. ↩
-
Echo (flat) uses 30-step Euler sampling on the RF ODE with independent CFG (text = 3., speaker = 5.0), cfg_min_t = 0.5, truncation_factor = 0.8, temporal score rescale k = 1.2 and sigma = 3. Echo (sharp) changes: truncation factor = 0.9, temporal score rescale k = 0.96. Higgs Audio v2 samples are produced with the official repo (https://github.com/boson-ai/higgs-audio) and default settings (temperature = 0.3). VibeVoice-7B samples are produced using the VibeVoice community fork https://github.com/vibevoice-community/VibeVoice with default settings (cfg scale = 1.3). ↩
-
Podcast 0 Echo (flat) sample resampled with 60 Euler steps instead of 30 (same random seed).
↩ -
It might be more exact to orthogonalize the concatenation of up-projections, but we felt it might be interesting to have latents with some notion of varying importance along the latent dimension. With this PCA approach, the variances of the individual channels are now non-uniform; in some early ablations that may or may not be replicable, we found that per-channel normalization did not help (seemed to hurt), and that a random rotation of the latent space that resulted in roughly uniform channel variances also did not help (though didn’t significantly hurt). Given this, and the possibility of inference methods that exploit the PCA representations (left for future work), we choose to use this PCA approach. We transform this representation by a scalar, which was determined empirically (and roughly) through a few ablations. ↩
-
model = EchoDiT( latent_size=80, model_size=2048, num_layers=24, num_heads=16, intermediate_size=5888, norm_eps=1e-5, max_seq_len=640, text_vocab_size=256, text_model_size=1280, text_num_layers=14, text_num_heads=10, text_intermediate_size=3328, text_max_seq_len=768, speaker_patch_size=4, speaker_model_size=1280, speaker_num_layers=14, speaker_num_heads=10, speaker_intermediate_size=3328, speaker_max_patched_seq_len=640, timestep_embed_size=512, adaln_rank=256 ) -
Unnecessarily, but this is carried over from earlier setups where the same encoder is used for prefix representations for generating continuations; see section on block-wise sampling later (which helps justify the decision in this setup). ↩
-
There are separate w_k and w_v projections for each modality (so 3 w_ks and 3 w_vs). ↩
-
The final approach is a bit convoluted but involves, with some probabilities, choosing either
a) concatenating individual segments (to a random length < 120 seconds), each of whose composition ratio is similar to target or b) concatenating segments to some length such that the total composition ratio falls into some randomly selected bin (with something like most probability mass in 0.66< r < 1.5, but some probability mass in lower/higher ratios, in some sense to add “slack” or flexibility to the model). This path involves precomputing candidate segment sequences and crop lengths. ↩
-
patch size of 4, so output will be length 160 ↩
-
with some probabilities, we only use 1 or 2 segments ↩
-
we apply RoPE to first half of heads with properly-patch-dilated time indexing ↩
-
technically (as the encoder is causal) only need to process the most recently generated latents if we have the encoder kv cache of earlier generated latents ↩
-
with proper RoPE offsets ↩